之前几段工作经历都与搜索有关,现在也有业务在用搜索,对搜索引擎做一个原理性的分享,包括搜索的一系列核心数据结构和算法,尽量覆盖搜索引擎的核心原理,但不涉及数据挖掘、NLP等。文章有点长,多多指点~~
一、搜索引擎引题
搜索引擎是什么?
这里有个概念需要提一下。信息检索 (Information Retrieval 简称 IR) 和 搜索 (Search) 是有区别的,信息检索是一门学科,研究信息的获取、表示、存储、组织和访问,而搜索只是信息检索的一个分支,其他的如问答系统、信息抽取、信息过滤也可以是信息检索。
本文要讲的搜索引擎,是通常意义上的全文搜索引擎、垂直搜索引擎的普遍原理,比如 Google、Baidu,天猫搜索商品、口碑搜索美食、飞猪搜索酒店等。
Lucene 是非常出名且高效的全文检索工具包,ES 和 Solr 底层都是使用的 Lucene,本文的大部分原理和算法都会以 Lucene 来举例介绍。
为什么需要搜索引擎?
看一个实际的例子:如何从一个亿级数据的商品表里,寻找名字含“秋裤”的 商品。
使用SQL Like
select * from item where name like '%秋裤%'
阅读全文
从简原则,如果是一些小笔记的话,会在 note 项目下的 issue 上面写,支持Markdown,也可以有评论。
https://github.com/Yhzhtk/note/issues
多谢关注!
阅读全文
事务是数据库操作原子性的最基本手段,而事务的传播级别和数据隔离级别,是事务控制的两个主要特性。传播级别定义的是事务的控制范围,事务隔离级别定义的是事务在数据库读写方面的控制范围。上篇文章主要分析了隔离级别的问题,这篇文章看看事务的传播性。主要以Spring中的事务传播性来说明。
Spring事务传播性有七种,REQUIRED、SUPPORTS、REQUIRES-NEW、NOT-SUPPORTED、MANDATORY、NEVER、NESTED。画了一个思维导图,以图学习各个传播级别的区别和特点吧。
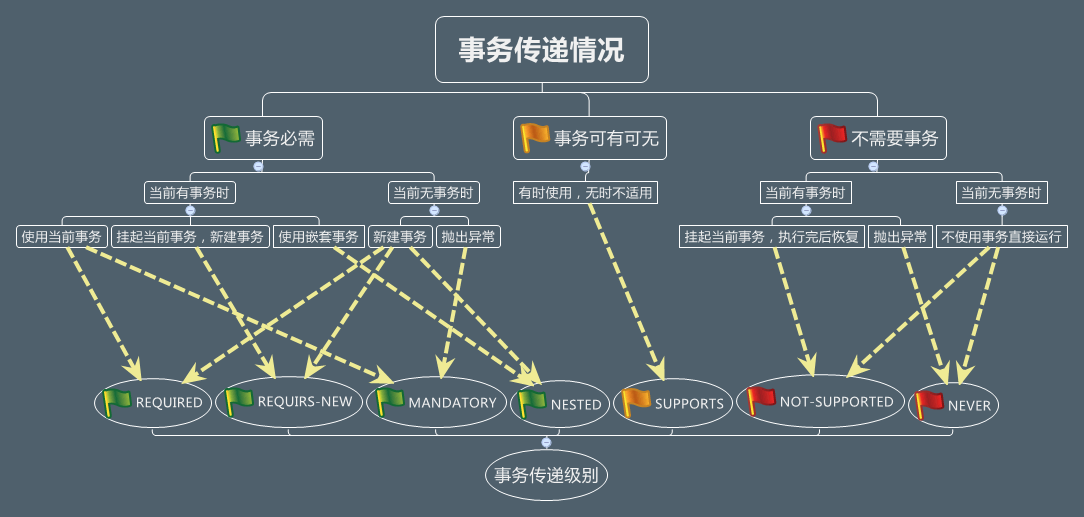
阅读全文
数据库的并发操作时,很可能会出现不一致的问题,包括丢失的修改,读脏数据,不可重复读,幻影读等,这些可以通过最原始的共享锁和排他锁解决,但是使用锁复杂繁琐,便产生了隔离级别,针对具体的业务流程使用不同的隔离级别,从而解决并发不一致的问题。
并发不一致问题
多个对象同时进行数据库操作时,由于先后顺序、读写操作、读写内容的各种组合,可能会出现丢失的修改、读脏数据、不可重复读、幻影读四种不一致的情况。以下描述中A、B表示两个线程中的操作对象:
- 丢失的修改:A、B读完后,都修改后写入。那么最终的结果是后一个修改的,而前一个修改被覆盖丢失了。
- 读脏数据:A读取到了B未提交的数据,当B回滚撤销时,A读到的数据就是错误的脏数据了。
- 不可重复读:A读数据后,B对数据进行了修改,A再读取时,就发现数据不一致了。
- 幻影读:A读取数据后,B又新增了一条记录,A再读时,发现多了一条,好像出现了幻觉一样。
阅读全文
复习了一下设计模式,发现有些没用过,没理解,还是不熟悉,翻看一遍,用一句话总结一下,希望能加深记忆,在使用中不断理解。
设计模式三个大类:
- 创造型设计模式:创造,就是产生一个新对象。
- 结构型设计模式:结构,注重设计架构,一些可直接参考的结构体系,可理解为整体模型。
- 行为型设计模式:行为,是动态的,注重调用、改变等动作。
阅读全文
 RSS订阅
RSS订阅
